#25 Поисковые системы по данным как глобальные системы обнаружения данных

У поисковых систем довольно обширная история. Их можно использовать для поиска текстов, веб-страниц, изображений, видео и новостей, а также всякого разного другого контента используя такие глобальные поисковые системы как Google или Bing Google или Bing.
Можно использовать также не такие популярные поисковые системы как You или DuckDuckGo.
Но только лишь некоторые поисковые системы поддерживают поиск по наборам данных. Среди них, на первом месте Google Dataset Search
Google Dataset Search
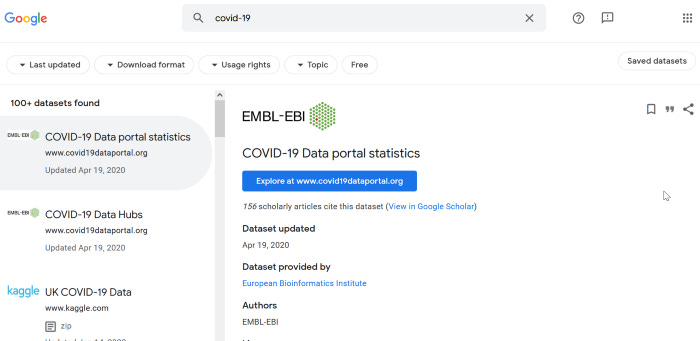
Это был исследовательский проект созданный Google в сентябре 2018 года и вышедший из беты в январе 2020 г.
Это одна из наиболее продвинутых поисковых систем про данные и в её основе стандарт Schema.org с типом данныхDataset.
Его можно описать как JSON данные (метаданные) помещённые внутрь страниц HTML.
Я не могу сказать точно насколько полон индекс Google Dataset search, но он довольно велик и включает такие источники данных как:
А также многие другие, использующие структуры Schema.org для каждого доступного набора данных.
Но Вы можете обнаружить что далеко не каждый портал открытых данных поддерживает Schema.org. Например, портал данных Правительства Индии data.gov.in. Он весьма велик и включает более чем 534 118 цифровых ресурсов и он индексирован основной поисковой системой Google, но не индексируется Google Dataset search.
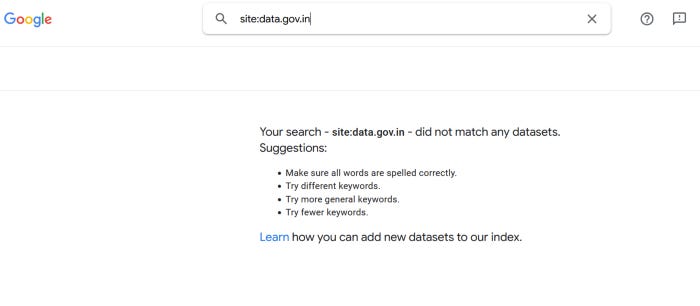
Аналогичная ситуация с порталом открытых данных Росссии data.gov.ru, Индонезийским порталом данных data.go.id, и многих других общественных и государственных порталов открытых данных.
Идея того что владельцы сайтов должны описывать наборы данных самостоятельно с использованием Schema.org имеет свои ограничения. Не каждый владелец порталов данных знает об этом или других страндартах и не каждое ПО каталогизаций данных поддерживают Schema.org.
DataCite Search
Другая поисковая система это Datacite Search (search.datacite.org). Она куда более сфокусирована на работе учёных в исследовательских задачах.
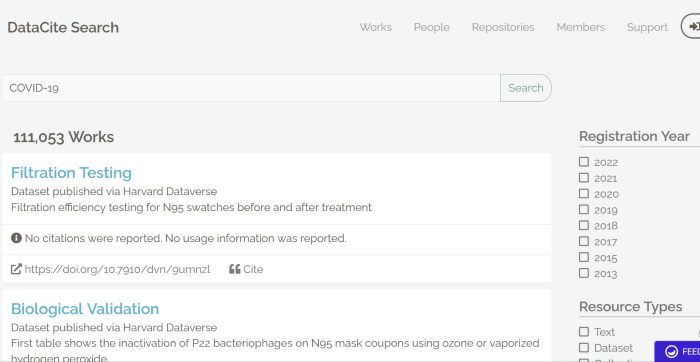
DataCite присваивают идентификаторы DOI каждому цифровому ресурсу предоставляемого их пользователями и индексирует исследовательские репозитии в части текстов и данных. Оно включает схему метаданных для описания наборов данных и других цифровых артефактов относимых к исследовательским статьям и иным публикациям. .
DataCite индексирует из данные из таких порталов данных как Zenodo, UBC Library Open Collections, Data Inrae и Harvard Dataverse.
Но оно не покрывает наборы данных за пределом экосистемы DOI, поэтому коммерческие наборы данных или порталы открытых данных органов власти не попадают в поиск DataCite
Ограничения поисковых систем
Обе поисковые системы индексируют доступные им наборы данных, но они не индексируют содержание наборов данных. Обе поисковые системы построены лишь на базовых метаданных о наборах данных. Datacite использует метаданные по их собственной схеме, а Google Dataset search использует определение Dataset стандарта Schema.org:
Но они не позволяют:
искать по метаданным уровня наименования поля в файле, базе данных, таблице.
искать по содержанию набора данных.
Даже поиск по метаданным ограничен его областями применения. Сейчас несложно процитировать найденный набор данных, но нет возможности сразу и быстро его использовать.
Описания наборов данных может быть неполным, выгрузка набора данных может требовать авторизации или иных дополнительных шагов.
Инструменты обнаружения данных построены иначе
Существует множество каталогов для обнаружения данных используемых в корпоративной среде. Многие стартапы и решения открытыми кодом такие как Open Metadata, Amundsen и Datahub помогают обнаруживать и документировать таблиц баз данных и иные артефакты инженерии данных, таких как визуализации, трубы данных и многое другое. Некоторые из этих каталогов также поддерживают файлов наборы данных. Но ничего такого нет в мире порталов открытых данных и научных репозиториев данных.
Вы можете искать конкретные названия полей таблиц, их типы и семантические типы данных, также называемые бизнес глоссарием, в корпоративном каталоге данных и Вы не можете делать то же самое для открытых данных. Глобальные поисковые системы для данных такие как DataCite Search и Google Dataset Search не умеют выполнять такую задачу.
Но это не невозмжно реализовать. Есть несколько спецификация для API в порталах и репозиториях данных. Это CKAN API, OpenDataSoftAPI и Socrata API. Например, Socrata API активно используется стартапом Splitgraph для публичного каталога данных где данные структурированы в базы Postgres.
Поисковая система - это глобальная система обнаружения данных
Я вижу что поисквая система для наборов данных - это система обнаружения данных. Поиска по базовым метаданным недостаточно. Должны быть возможности сравнимые с корпоративными каталогами данных:
Поиск по расширенным метаданным
Поиск по тексту/данным внутри набора данных.
Также поисковая система не должна быть ограничена только научными данными и только стандартом Schema.org. Любая глобальная система обнаружения данных должна поддерживать все способы индексации данных включая Schema.org и известные протоколы и стандарты такие как DCAT, OAI-PHM и другие.
Я также считаю важным интегрировать семантические типы данных в систему обнаружения данных и возможность поиска по данным.
Напишите что Вы думаете о том как должны работать поисковые системы по данным и что важно для Вас в задачах поиска данных.
P.S. Эта заметка перевод моей англоязычной заметки на Medium.