Хорошие и плохие практики публикации данных. Метаданные и форматы файлов
«Буду делать хорошо, и не буду — плохо». (Маяковский)

Открытые данные, открытые API для доступа к данным, коммерческие API для той же цели, коммерческие сервисы продажи данных и дата маркетплейсы - это то что они создаются в форме дата продуктов.
Цель их создания, и не важно почему, из коммерческих интересов или регуляторных требований, в охвате целевой аудитории и предоставления данных пользователям наиболее удобным образом.
Так должно быть, вернее очень бы хотелось. При этом реальность наполнена как очень хорошими, так и откровенно плохими практиками предоставления данных.
Плохие открытые данные
Некоторые такие плохие практики раньше публиковались во французском проекте OpenDataFail, но сейчас от него остался только Twitter. Ещё был проект Bad data от Open Knowledge Foundation, с несколькими примерами плохой публикации данных. Я туда также, ещё много лет назад отправлял несколько примеров особенно плохих публикаций данных в РФ. Хотя это было давно, но до сих пор отчетливо помню когда обнаружил что на сайте российского МВД публиковались XML файлы разметки MS Word и они выдавались за открытые данные.
MS Word позволяет сохранять текстовые документы в XML формате, он называется Word 2003 XML document. Эти файлы не являются файлами с данными, это всего лишь язык разметки, также как HTML или другой формат публикации текста.
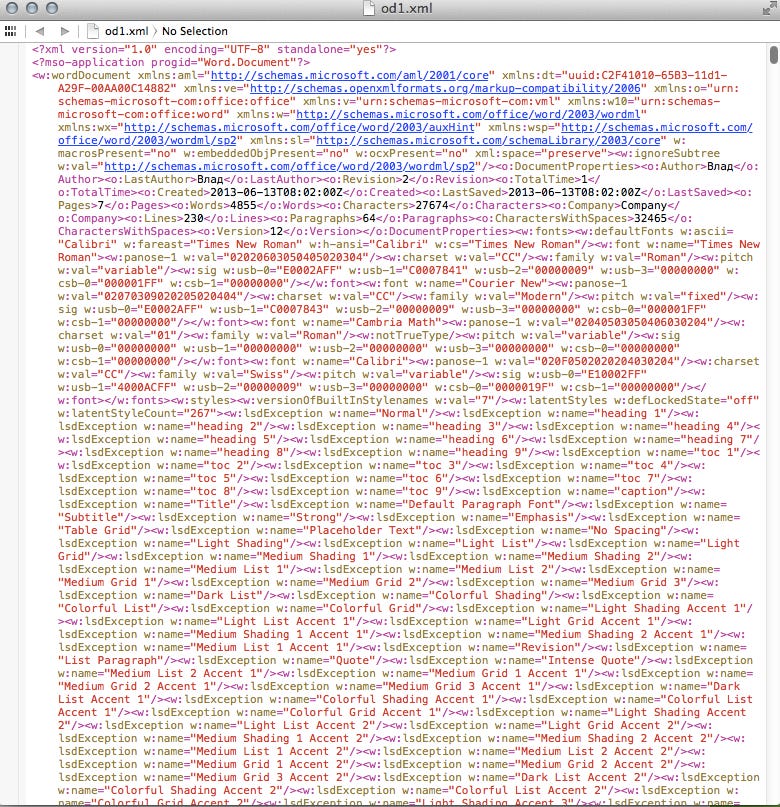
Почему этот случай такой заметный? Потому что оригинальные данные явно были в формате .doc или .docx. Вместо того чтобы сохранить их в Excel или CSV, сотрудники МВД сохранили их в формате Word 2003 XML document. Который, как бы XML, но какого-либо удобного способа получения из него данных нет.
Этот пример один из наиболее одиозных и редких. На практике же качество данных складывается из множества параметров и начинается с метаданных.
Метаданные
Метаданные — информация о другой информации, или данные, относящиеся к дополнительной информации о содержимом или объекте.
Можно сказать что метаданные - это данные о данных. Они описывают основные характеристика любого цифрового объекта таким как документы, научные статьи, репозитории кода и к которым, безусловно, относятся и наборы данных и открытые API. Важность метаданных очень хорошо понимают библиотекари и архивисты, в архивном деле давно распространён такой стандарт как MARC 21 для библиографии, а также такой общепринятый стандарт описания цифровых объектов как Dublin Core.
Если перевести понятие метаданных в практическое русло, то они отвечают на такие вопросы пользователей как:
Что это такое?
К каким предметным областям это относится?
Когда оно было создано и изменено?
Как это получить/скачать (ссылка) ?
Кем оно создано и кто за это отвечает? Как с этим человеком/организацией связаться?
Что с этим связано?
В каком формате оно распространяется?
Имею ли я право это использовать и если да то какие ограничения ?
Можно обратить внимание что базовые метаданные отвечающие на эти вопросы такие как: название, описание, дата создания, ссылка, условия использования/лицензия, автор, контакты автора и многое другое универсальны.
В большинстве типовых решений, каталогов данных, порталов открытых данных или научных репозиториях присутствует хотя бы базовый уровень из Dublin Core, а также многое специфичное именно для датасетов, особенно разного типа.
Отдельно можно выделить несколько стандартов метаданных которые, можно сказать, являются общепринятыми:
DCAT2&3 стандарт публикации датасетов от W3C со множеством расширений в разных странах таких как DCAT-AP в Евросоюзе, DCAT-US в США. Наиболее проработанный стандарт описания наборов данных, поддерживается многими каталогами данных и расширениями для них.
Schema.org Dataset используется для индексации датасетов в поисковиках, в первую очередь в Google. Адаптирован для использования в разметке веб страниц и расширяет спецификацию CreativeWork, также из Schema.org. Имеет смысл использовать его если Вы хотите чтобы Ваши данные было легко найти.
Карточка набора данных в CKAN основна изначально на базе Dublin Core, и при этом расширяется. Даёт возможность заполнить минимально необходимое описание набора данных. Используется в ПО CKAN и DKAN, для потребителей данных доступна через CKAN или CKAN совместимое API.
Кроме этих стандартов существует ещё множество других, также, активно применяемых при публикации данных. Это и уже упоминавшийся ранее Dublin Core, и стандарт DataCite для научного цитирования, и CodeMeta, и MARC XML и многие другие. Большое число стандартов для описания и публикации метаданных существует для пространственных данных, можно сказать это отдельная область описания датасетов.
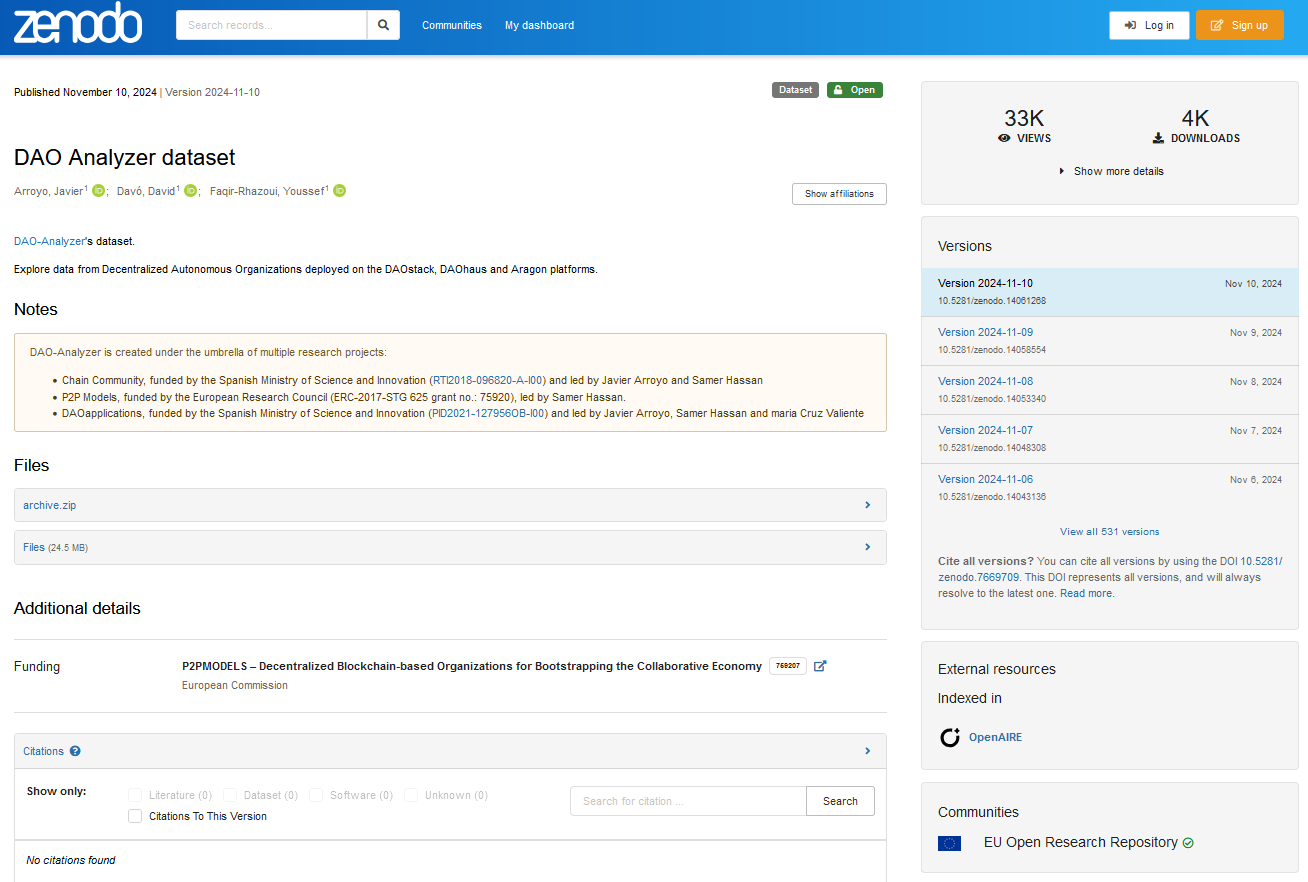
Те же метаданные экспортированные по спецификации DCAT
Можно сказать что метаданные - это базовый уровень качества данных. Многие порталы, так то общеевропейский портал data.europa.eu отображают сведения о качестве именно метаданных датасетов.

Поэтому, с одной стороны, может показаться что метаданные это сложно, но на самом деле это совсем не так и здесь мы приходим к первому практическому совету.
Совет первый. Используйте стандартизированное ПО для публикации каталогов данных всегда когда это только возможно.
Большая часть ПО для каталогов открытых данных и онлайн платформ для их размещения требуют заполнения базовой информации о датасетах, поддерживают множество дополнительных атрибутов и экспорт во множество стандартов метаданных. К таким ПО можно отнести CKAN, DKAN, InvenioRDM, Harvard Dataverse, ArcGIS Hub, GeoNode, Geonetwork и OpenDataSoft, а к платформам Zenodo, Kaggle, Hugging Face и многие другие.
Четко сформулированные метаданные и контроль их заполнения общеприняты для публикации научных данных и данных имеющих пространственную привязку, из научной среды они, во многом, перекочевали в порталы открытых данных и такие спецификации как DCAT.
Для коммерческих дата продуктов такое тщательное заполнение метаданных это скорее редкость. Владельцы коммперциализируемых баз данных или датасетов, как правило, гораздо больше внимания уделяют снятию барьеров в доступности данных и качеству документации, а из спецификаций реализуют только Schema.org для повышения находимости в поисковых системах.
Хорошо заполненные метаданные не только делают данные более доступными и понятными для пользователей, но и повышают их видимость в поисковых системах и улучшают интегорированность, и дата каталогов и отдельных датасетов с другими системами и продуктами.
Ссылки и внутренние и внешние данные
Большая часть порталов открытых данных и онлайн платформ поддерживают, как загрузку данных во внутреннее хранилище данных, так и указание внешних ссылок. Как правило у одного набора данных присутствует от одного до нескольких ресурсов, файлов, или ссылок.
Хорошая практика, при этом, загружать данные в то ПО/тот онлайн сайт/ресурс на котором работает этот каталог данных.
Совет два. Во всех случаях когда можно загружать данные внутри каталога данных или платформы, лучше так и делать.
Почему это важно? Не последняя проблема с общедоступными данными и иными цифровыми артефактами - это их исчезновение. В некоторых областях создания знаний к этому относятся серьёзно и, например, в научной среде есть практики архивации, как минимум, результатов научной деятельности. Архивация датасетов значительно проще когда данные находятся в рамках одного сайта/одной платформы и значительно сложнее когда опубликованы ссылки на внешние ресурсы.
Приведу пример из личного опыта. Анализируя и выгружая все доступные данные из нескольких порталов открытых данных в 2023 году, при подготовке проекта Dateno я столкнулся с тем что около 10% ссылок на портале data.gov.uk были нерабочими. Этот портал выступал агрегатором ссылок на муниципальные порталы данных страны и на многих из них обновлялось ПО сайта или менялся домен и ссылки более не вели на данные или не работали вовсе.
Форматы файлов
Следующий шаг при публикации данных - это выбор правильных форматов, API и то как и где они доступны. Эта задача, часто воспринимается упрощённо и её общепринятое решение звучит как.
Совет три. Не знаешь как опубликовать, публикуй CSV или JSON.
Но на практике есть много нюансов и вариаций.
Действительно, CSV, формат текстового файла для публикации таблиц, в котором значения разделены запятой, является наиболее популярным для распространения данных. Большая часть открытых данных в мире опубликованы в CSV формате и из многих порталов открытых данных и геопространственных продуктов он экспортируется по умолчанию.
CSV удобен своей простотой, человекочитаемостью, отсутствием требований к специализируемому ПО, возможностью работать в любой среде и любой платформе и на оборудовании с минимальными требованиями. А, при необходимости, данные CSV можно сжать в формат Gzip и уменьшить размер, сохранив возможность его обработки.
Такой подход используется очень давно, и он был бы универсален если не некоторые особенности в работе с данными в последнее время:
не все данные можно уложить в плоские таблицы и в этом случае CSV файлы использовать неудобно. Для таких случаев гораздо логичнее файлы JSON, JSON lines или XML;
Большая часть стандартов публикации данных были разработаны под поддержку схем описания данных для XSD для XML или JSON Schema для JSON и описания текстом.
У CSV много диалектов и множество ошибок возникает при чтении CSV файлов с нестандартными разделителями или включающее тексты с переводами строк. CSV формат, в принципе, не приспособлен для публикации данных с большими текстами.
CSV формат, даже со сжатием, менее эффективен чем современные форматы такие как Parquet где достигается колоночное зжатие данных.
Итак, в каком формате лучше всего публиковать данные? Вариантов много, многие весьма специфические/отраслевые
XLS, XLSX, ODS - наиболее распространённые форматы файлов используемые в Microsoft Excel и Libre/OpenOffice. По факту являются скорее не дата файлами, а языками разметки таблиц и импорт из них в СУБД или использование эти данных машинным образом скорее затруднено. Имеет смысл использовать на практике только когда Вы публикуете какие-либо унаследованные данные или если Ваши пользователи точно планируют использовать их в редакторе типа Excel, но и в этом случае лучше дополнить их машиночитаемыми данными, например, в CSV.
CSV - наиболее популярный формат для публикации данных. Очень распространён и очень часто содержит ошибки в форматировании. Хорошо подходит для публикации плоских таблиц, но плохо для любых иерархических данных.
XML - расширенный язык разметки. Плюс в возможности валидации данных через XML схемы. Часто используется для публикации данных по определённым стандартам и из существующих информационных систем. Можно публиковать данные в любой сложной иерархии. Минусы в том что обработка подобных данных требует более сложно парсинга и в том что очень крупные XML файлы могут требовать больших ресурсов для их обработки поскольку стандартные DOM парсеры загружают их в память целиком.
JSON - в полном названии, JavaScript Object Notation, фортмат данных получивший популярность с развитием веб приложений и использования JavaScript. Из плюсов хорошо поддерживает иерархию и множествотипов данных, из минусов, также как XML загружается полностью в память. Если JSON файл будет в несколько гигабайт, то и, как минимум, несколько гигабайт он займёт в оперативной памяти.
NDJSON / JSON lines / JSON streaming - альтернатива формату файлов JSON решающая задачу потоковой обработки данных без полной загрузки в оперативную память. У JSON lines каждая строка - это JSON объект и данные обрабатываются построчно. JSON lines значительно набрал популярность для экспорта данных в сложной структуре и он позволяет сохранять те данные которые так просто не сохранишь в CSV. Важным недостатком JSON lines является увеличение объёма итогового файла. Например, CSV файл в 3.5 ГБ после преобразования в JSON lines занимает 8.7 ГБ (~2.5 раза больше).
Apache Parquet - это специальный, колоночный формат файлов изначально использовавшийся в продуктах экосистемы Apache Hadoop с 2013 года и вышедший далеко за его пределы. Главные достоинства формата Parquet в удобстве для аналитической работы через ускорение запросов благодаря тому что данные хранятся по колонкам и сжатию данных превышающему сжатие CSV файлом с помощью Gzip, но без потери возможности работы с файлом. К примеру, CSV файл в 3.5 ГБ после преобразования в Parquet занимает 0.93 ГБ (~3,8 раз меньше).
Кроме того существует множество других форматов файлов за пределами наиболее популярных. Они не так популярны, приведу несколько примеров:
RData - формат с расширениями .rdata и .rda используется для распространения данных для инструментов на языке R
TSV - диалект CSV в котором в качестве разделителей используются символы табуляции. Чаще всего рассматривается просто как подвид CSV файла, но может иметь свое расширение .tsv
NetCDF - популярный в метеорологии и ряде других наук формат для публикации и распространения научных данных измерений
RDF, TTL, JSON-LD - семейство форматов используемых для публикации семантических/связанных данных
MAT - проприетарный формат данных используемый в приложении MATLAB. Часто используется для распространения данных в статистике и социологии.
А также существует множество форматов данных и API для публикации пространственных данных, но это тема отдельного большого текста. И не меньшее число форматов и способов публикации отраслевых данных, большая часть которых может иметь расширение .xml, но содержать данные по конкретной спецификации.
Вернемся же к наиболее популярным форматам файлов и способом публикации данных.
Итоговый формат данных почти всегда складывается из следующих пунктов:
В каком формате/форматах пользователи хотели бы использовать эти данные?
В какой формат данных мы можем преобразовать те что у нас есть ?
Какие технические ограничения у нас есть? (как правило речь про то сколько дискового пространства или ширина интернет канала у нас етсь)
В итоге, как же публиковать данные наиболее правильно?
Если данные являются плоскими то в CSV формате. Если размер CSV файла относительно велик, условно, начиная с 20 МБ, то сжать его Gzip или Bzip2 или Xzip или ZStandard.
Если данные не являются плоскими, то в формате JSON lines, опять же если файл достаточно велик, то сжать его как и CSV файл.
Если есть необходимость экономии дискового пространства и если среди пользователей есть дата аналитики и дата сайентисты, то дополнительно опубликовать данные в формате Parquet.
Если это специфичные отраслевые данные или геоданные, то воспользоваться одними или несколькими спецификациями. Например, GeoJSON для геоданных, или WARC для веб архивов, или PCAP для данных сетевого трафика и так далее.
Хотя и можно публиковать данные в Excel, это всё менее популярно, и в большинстве случаев сейчас данные публикуются как CSV с описанием разделителя. Большинство Excel пользователей умеют импортировать такие файлы.
Публиковать данные в форматах XML или JSON стоит только если они относительно невелики.
Про форматы данных можно рассказывать ещё много и я сознательно пока не затрагиваю тему пространственных данных.
Хорошие практики
Прежде чем приводить хорошие примеры надо оговориться что не все хорошие практики следуют рекомендациям выше и востребованность данных зависит не только от того как Вы публикуете метаданные и то насколько удобные форматы Вы используете.
Востребованность вот что важнее всего для любых данных. Если Ваши данные не нужны людям, то, в целом, неважно то насколько хорошо Вы их публикуете.
Тем не менее хорошие практики - это хорошие практики. Для востребованных данных они добавляют качество их пользователям.
Статистику хорошо публиковать, в столь многих востребованных форматах сколь это возможно: CSV, Excel, XML, JSON-Stat, SDMX (специальный формат распространения) и Parquet. А также предоставлять API. У статитистики более всего разных категорий пользователей. От дата аналитиков и дата инженеров до нетехнических пользователей. Так делают, например:
В Финляндии на портале данных статистики работающих на ПО PxWeb с экспортом в более чем 10 форматов.
На портале данных ЮНЕСКО с экспортом в CSV, Excel и общедоступным API отдающим данные в формате SDMX.
На национальном портале открытых данных Малайзии с публикацией данных в форматах CSV и Parquet, с открытым API и автоматически сгенерированным кодом доступа к данным
Из всех диалектов для CSV файлов наиболее практичный самый распространённый Excel-диалект, с разделителем в виде запятой. Во первых его понимает большая часть программных продуктов по умолчанию (кроме самого Excel) и во вторых Github по умолчанию отображает CSV как таблицу только для этого диалекта. Если Вы загрузите в репозиторий Github данные с разделителем табуляцией, то файл будет выглядеть как текст.
При выборе форматов сжатия файлов с данными правильный выбор зависит от того насколько Вы понимаете потребности аудитории/пользователей. Если Вы публикуете архивные унаследованные форматы файлов, то можно сжимать их как можно лучше используя Xzip или Bzip2. Если Вы хотите опубликовать сразу много файлов, то лучше запаковывать их в ZIP файлы. А если Вы хотите опубликовать файлы которые было бы удобно использовать аналитиками то лучше использовать компрессию Gzip или Zstandard.
Почему ZIP, а не 7z, Rar или Tar.gz ? Две причины. Первая в том что ZIP файлы многие порталы данных умеют листать и отображать их содержимое при любом размере файла, например, такое поддерживает Zenodo. Вторая в том что для ZIP файлов во многих языках разработки есть возможность открытия файлов и потоковой обработке файлов прямо внутри ZIP контейнера. Для многих других форматов архивов, даже если есть программный код доступа, чаще всего нет возможности открывать файлы внутри для чтения и требуется распаковка архива до обработки файла.
Некоторые современные аналитические продукты поддерживают только определённые режимы компрессии. Например, DuckDB поддерживает компрессии Gzip и Zstandard, но не поддерживает ZIP. Если Вы попробуете команду select * from 'data.csv.zip'; она не сработает, а если select * from 'data.csv.gz';. Файлы, конечно, должны существовать для такой проверки.
Некоторые дата продукты являются хорошими примерами даже при некоторой архаичности их реализации. Например, система ФИАС Налоговой службы РФ содержит раздел для разработчиков включающий API, актуальные данные ГАР, данные в унаследованной форме КЛАДР, публикацию обновлений и полных версий наборов данных. При этом некоторые практики неудобны или архаичны, а другие, наоборот, более чем разумны:
Унаследованные архивы КЛАДР публикуются будучи сжатыми архиватором ARJ.
Полные версии сжатых XML файлов ГАР - это 42 ГБ. Требуется написание специального SAX парсера для доступа к данным.
Но все схемы данных хорошо задокументированы и описаны.
Но есть специальный сервис получения обновлений данных.
Для научных данных особенно актуальна публикация данных с присвоением DOI и ссылками на опубликованные данные. В этом случае точно не надо публиковать данные на произвольном сайте, а лучше воспользоваться одной или онлайн платформ или развернуть систему управления данными и научными результатами и публиковать в ней.
В этот раз получился особенно длинный лонгрид и я не успел рассказать и половины того что важно при публикации данных. В одном из последующих текстов я постараюсь далее раскрыть эту тему.