#31. Что не так с порталом открытых данных Узбекистана?
Будь таким, каким хочешь казаться. (с) Сократ

Среди множества порталов открытых данных созданных национальными правительствами на постсоветском пространстве особняком стоит портал открытых данных Узбекистана - data.gov.uz.
Помимом того что он не выглядит заброшенным, можно обратить внимание что на нём опубликовано 6623 набора данных больше чем на любом другом портале открытых данных кроме разьве что портала открытых данных Украины с 28 948 наборами данных и портала открытых данных РФ с 26 920 наборами данных. О них разговор отдельный, в другой раз, а сейчас заглянем что называется “под капот” портала открытых данных Узбекистана.
Несомненные достоинства
Для начала надо отметить его достоинства, а они есть։
данные все публикуются в машиночитаемых форматах CSV/JSON/RDF, а также в Excel
внутри портала используется некое структурированное хранилище, а то есть данные с самого начала хранятся в структурированном виде
структура данных хорошо описана, хотя и не публикуется в машиночитаемых форматах, тем не менее каждое поле документировано.
есть разделы мониторинга устаревших наборов данных, статистики и даже
Иначе говоря, с первого взгляда, портал выглядит весьма прилично. Кажется что его создатели всерьёз постарались над тем чтобы наполнить его данными и что это чуть ли не лучшая инициатива в Средней Азии как минимум.
Лично я люблю изучать такие примеры потому что каждый раз когда заглядываешь в то как устроены подобного рода порталы открытых данных ожидаешь найти хороший технологический или организационный подход, дающий возможность узнать что-то новое.
Учитывая что я достаточно давно работаю над анализом открытых источников данных и для этой цели индексирую существующие порталы открытых данных, то и в этом случае было несложно проделать эту работу.
Забегая вперёд скажу что всё не так хорошо как кажется, а “не быть, но казаться”, в данном случае, является наиболее точным утверждением.
Не быть, но казаться
Что меня лично смутило с самого начала - это такое число наборов открытых данных. В случаях когда на уровне центрального правительства устанавливают число опубликованных наборов данных как KPI его можно накрутить, например, публикуя данные ежемесячными слепками или публикацией одного и того же реестра множество раз, при каждом его обновлении.
Однако ничего такого, в данном случае не наблюдалось. Поэтому, много времени не заняло выгрузить весь портал открытых данных и посмотреть на его данные изнутри. Для простоты анализа данные были выгружены в формате JSON, но, в целом, в данном случае это большой роли не играло, поскольку все форматы данных на портале - это лишь разные представления одного и того же набора данных.
Итак, первая неприятная находка 2823 набора данных (42.6% от общего числа в 6623) это наборы данных размеров одну строку!
Посмотрим на такие наборы данных, например, один из них Получено яиц, всего по Хорезмской области
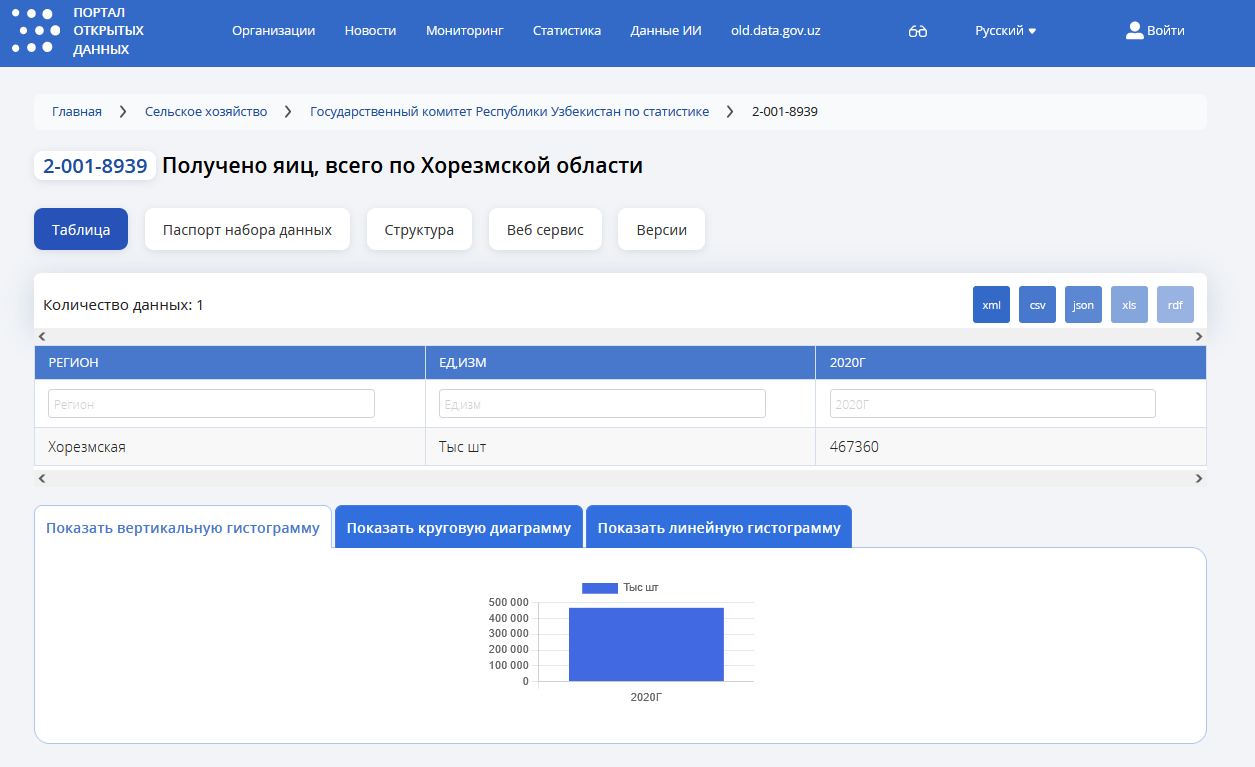
Одна строка, 3 колонки։ название региона, единица измерения и 2000г.
Но почему такой странный индикатор?? Если по виду товара ещё можно предположить что может быть индивидуальный индикатор, то по области точно нет. В Узбекистане 12 областей, одна республика и один город центрального подчинения, они все укладываются в один справочник по регионам.
Можно обратить внимание ещё и на то что эта практика повсеместна, для тех кто хочет изучить такие примеры выкладываю список из всех наборов данных имеющих размер в одну строку .
Навскидку, эти наборы данных можно сжать от 3 до 10 раз, большая их часть объединяется от 1 до 3 баз данных индикаторов с проработанными метаданными. Но даже если предположить что потенциальным пользователям могут быть нужны эти данные по индикаторам, даже в этом случае их будет сильно меньше.
Но и это ещё не всё․Для наглядности подсчитаем частоты встречамости наборов данных по их размеру. Вот тут можно увидеть конечные расчёты где в первой колонке число записей в наборе данных, а во второй число встречающихся наборов данных.
Выглядит это вот так.
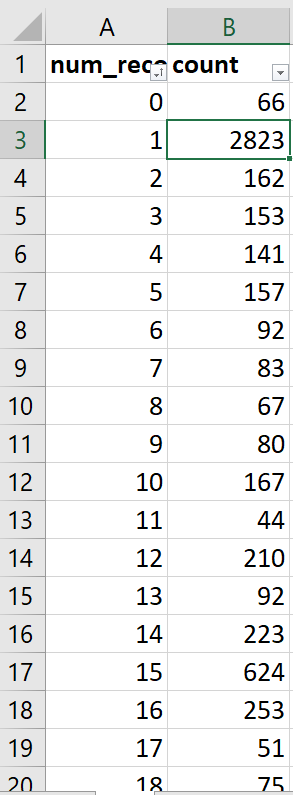
Давайте подсчитаем сколько всего наборов данных в которых присутствует менее 200 строк? Это 6381 набор данных, что-то многовато. Если сравним с общим числом наборов данных то это означает что 96.3% всех наборов данных на портале data.gov.uz - это сверхмалые данные.
Есть ли там данные побольше? Самый большой набор данных Сведения о победителях открытого конкурса на право аренды земельных участков сельскохозяйственного назначения содержит 60 984 записи общим объёмом в 25Мб в довольно избыточном JSON формате и всего 4.4Мб в виде CSV файла.
Это подтверждается и тем что общий объём данных, экспортированных в CSV формат составляет всего 40 мегабайт!
Итого, у нас есть 6623 набора данных из которых 96% - это сверхмалые данные, а общий объём всех данных 40Мб.
Мониторинг которого нет
Особая история с мониторингом актуальности наборов данных. Это, в целом, неплохая идея и способ контролировать актуальность данных. На портале data.gov.uz есть соответствующий раздел и даже утверждение о том что 6120 обновлены․
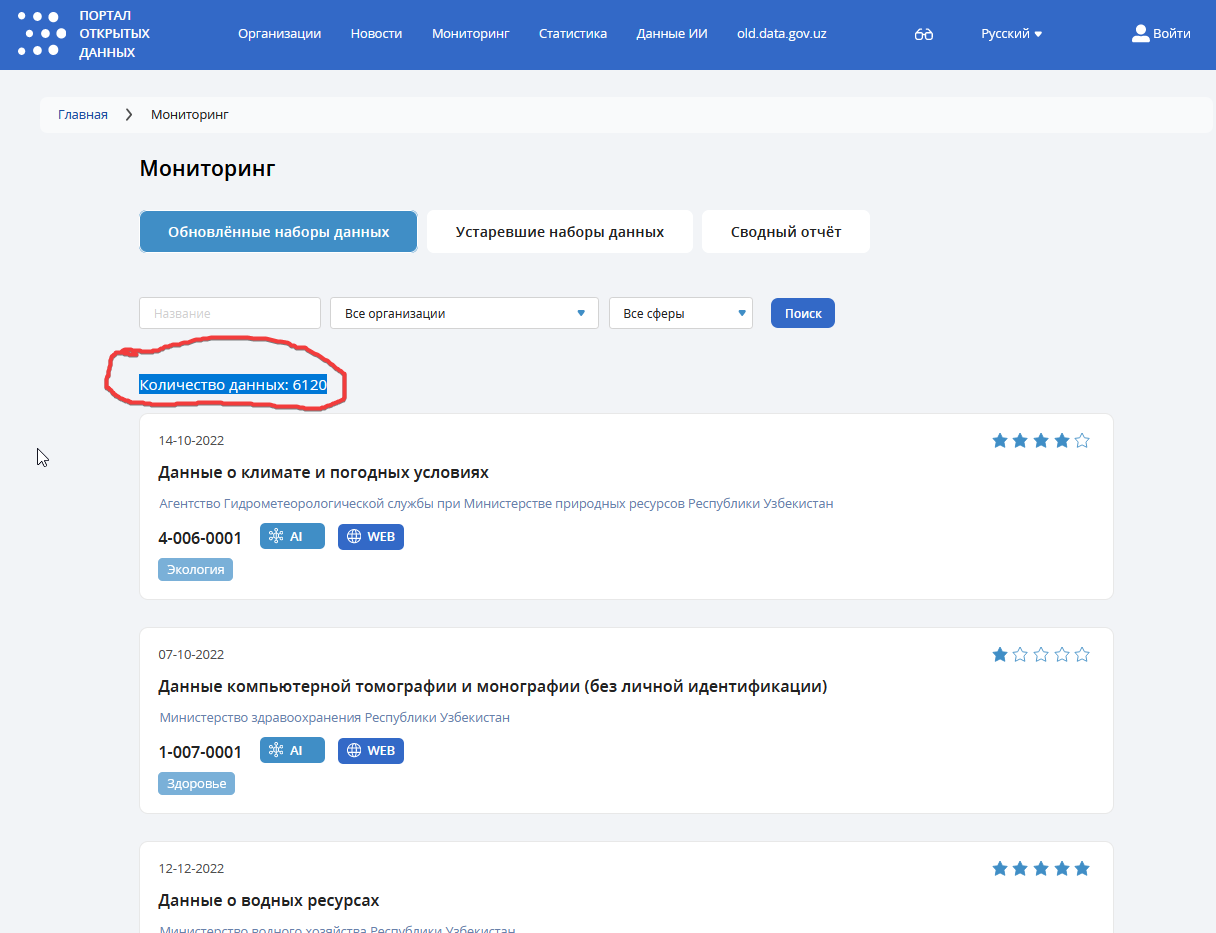
Посмотрим всё на тот же набор данных Получено яиц, всего по Хорезмской области. А он, оказывается, есть в этом мониторинге и отмечен как обновлённый набор данных.
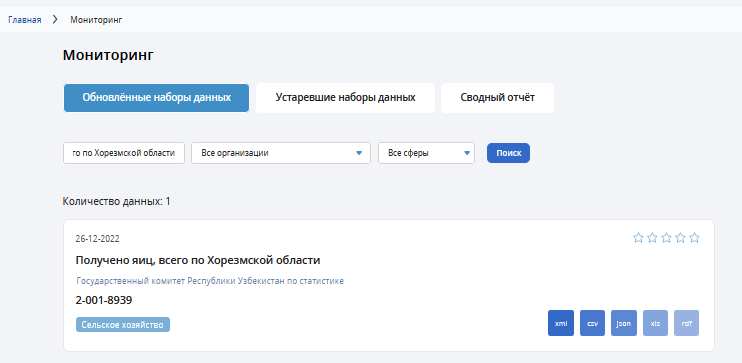
Это же подтверждается и в паспорте набора данных где последним обновлением указано что данные обновлялись в 26 декабря 2022 г. Но, как это возможно в ситуации когда там одна единственная цифра за 2020 год? Чему там обновляться?
Очень похоже с большинством всех остальных наборов данных, каждый надо проверять автоматически или вручную, но в случае статистических показателей это особенно просто. Готовые показатели не могут обновляться часто, раз в год, и не более того.
Не всё то RDF что так называется
Важная особенность портала открытых данных Узбекистана - это декларируемая поддержка формата RDF. RDF - это такой очень продвинутый стандарт публикации данных, требующий создания или использования существующих онтологий и интеграции данных в соответствии с ними. Публикация RDF файлов, обычно, происходит чаще по итогам научных работ или довольно сложных исследовательских проектов по публикации открытых государственных данных. Иначе говоря массовое использование этого формата говорит, или о гениальности, или о некой манипуляции.
RDF формат используемый на data.gov.uz, на самом деле, никакого практического применения не имеет.
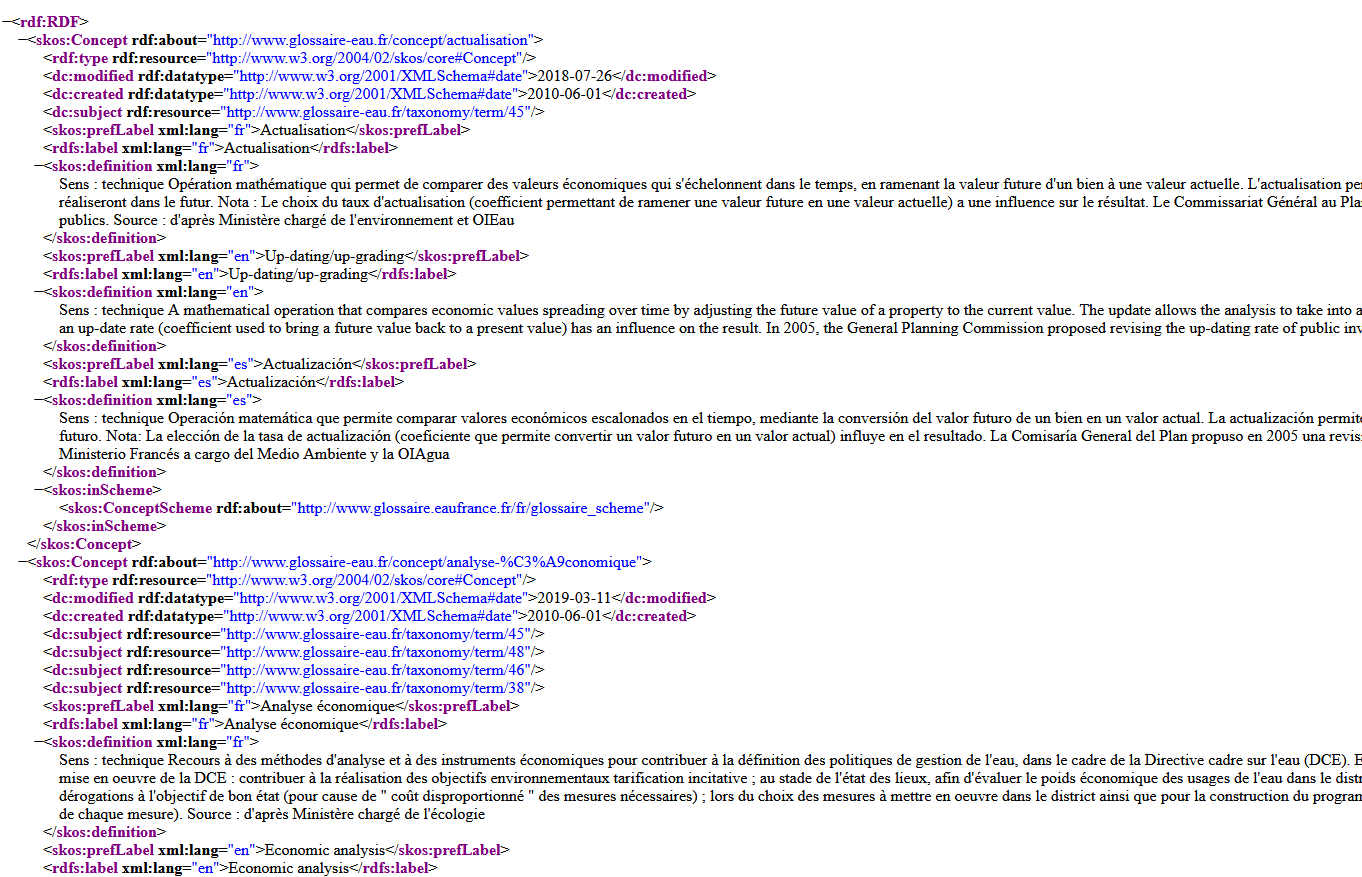
Он выглядит вот так и мало чем отличается от экспорта просто в XML, подвидом которого он является.

Для сравнения, на портале открытых данных Франции опубликовано всего 13 наборов данных в формате RDF, интегрированных с существующими онтологиями, как минимум с онтологией SKOS.
Например, так выглядят RDF данные французского глоссария информационных систем.
Итого
Выводы очень неутешительны. 6623 набора данных в итоге оказываются всего лишь 40 мегабайтами данных, а фактическое число наборов данных оказывается искусственно раздутым. Мониторинг наборов данных выполняет даже не декоративную, а скорее манипулятивную функцию не давая реальной картины, но показывая обновлёнными данные которые совершенно точно не обновлялись. Даже портал открытых данных Киргизии, при всего лишь 646 наборах данных в Excel оказывается больше по объёму, не говоря уже о многих других порталах открытых данных других стран.
Здравствуйте Иван! Меня зовут Акром Султанов. Я занимаюсь развитием открытых данных в Узбекистане. Прочитал Ваш "Лонгрид". С некоторыми мыслями согласен, с некоторыми нет. Поэтому предлагаю организовать совместное мероприятие (вебинар, онлайн-обсуждение и т.д.) и/или по возможности постараемся пригласить Вас на наши будущие мероприятия, в которых можем обсудить текущее состояние Портала и открытых данных в нашей стране. Нам будет интересно услышать Ваши идеи и советы по дальнейшему развитию этой сферы в Узбекистане.