Обновления в Dateno
Статистика, API, новые фасеты и ещё больше данных.

В течение последних месяцев я был настолько занят увлекательной работой над проектом Dateno что нехватало времени на написание лонгридов здесь и где бы то ни было.
Dateno - это проект создания крупнейшего поискового индекса по всем наборам данных что есть в мире.
В недавнем обновлении мы загрузили в него ещё 4 миллиона карточек датасетов и теперь общий объём индекса достиг 19 милллионов записей. Много это или мало? Поиск по данным от Google (GDS) на начало 2023 года содержал 50 миллионов записей. Поэтому это немало и вполне может быть ещё больше.
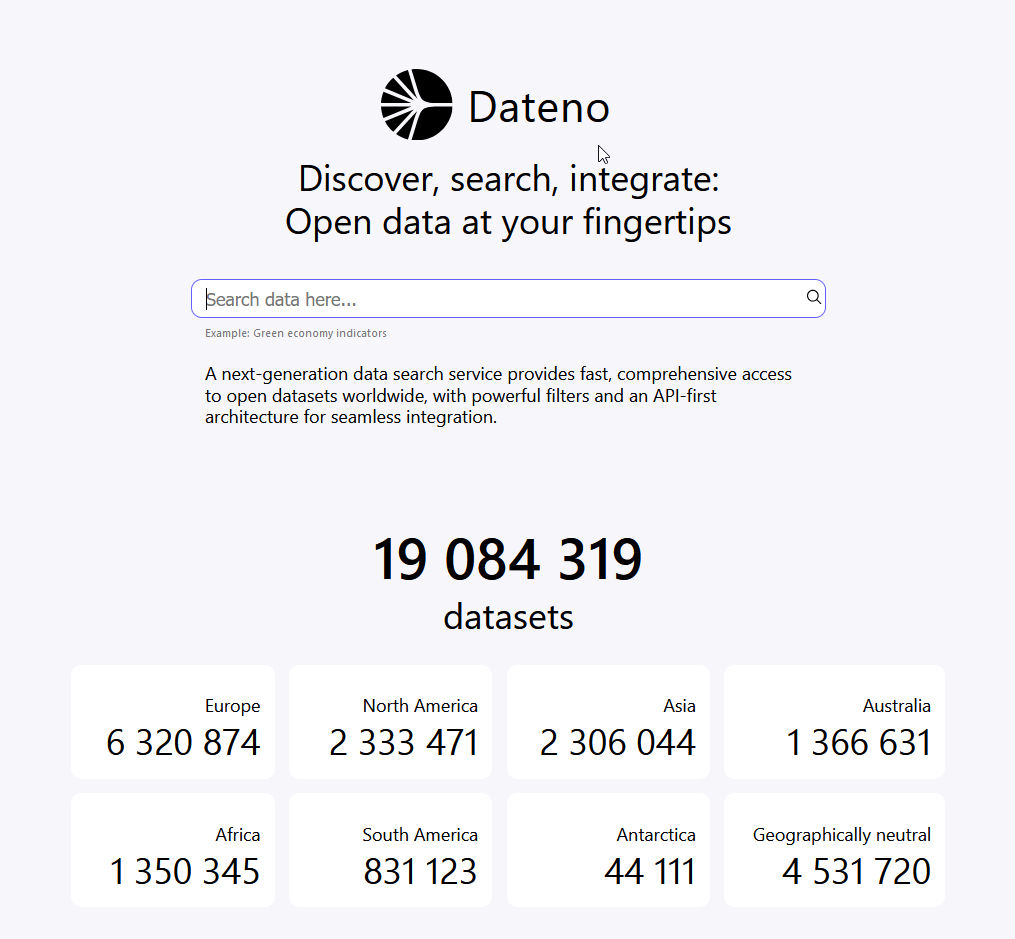
Здесь есть чем гордится и ещё немало работы предстоит. Потому что данных много, но пользователям важно ещё и удобство работы с ними. Важна возможность не просто найти данные, но и интегрировать в свою работу.
Поэтому ещё на старте проекта мы закладывали в него несколько принципиальных особенностей, отличающих его от других проектов по поиску данных:
Открытость
Может звучать странно применимо к поисковому индексу, но ведь важно из чего он состоит. Особенность Dateno в том что все источники данных из которых он формируются собраны в специальном открытом реестре Dateno registry в котором собраны все метаданные каждого источника данных используемого в Dateno. Это большая, в основном ручная работа, благодаря которой существуют многие фасеты в Dateno и именно она позволяет обеспечить значительную часть работы по качеству и полноте поискового индекса.
Другая часть открытости - это детальная статистика индекса доступная онлайн. В репозитории dateno-stats собрана статистика текущей версии индекса и предыдущей.

Сейчас статистика доступна в виде множества CSV и JSON файлов, далее мы развернём BI систему в дополнение к этим данным. Уже сейчас можно оценить охват по странам, языкам, программному обеспечению, лицензиям и многому другому.
Интегрируемость
У Dateno есть открытое API, достаточно лишь зарегистрироваться на сайте dateno.io и воспользоваться ключом для доступа к поиску и получению отдельных записей, как описано в документации на сайте API api.dateno.io.

А в качестве примера сделана утилита командной строки datenocmd с помощью которой можно искать данные так же как через веб интерфейс и которая доступна с открытым кодом.

Широта
Одна из особенностей Dateno, это многочисленные фасеты/фильтры используемые для уточнения поиска. Для поиска по датасетам сложно искать иначе кроме как по фильтрам поскольку для поиска не работают алгоритмы вроде PageRank поскольку на датасеты может и не быть ссылок.
Сейчас в Dateno 13 подобных активных фильтров, это:
Тип каталога данных
Тип владельца каталога
Макрорегион
Страна/Регион
Территория в стране (субрегион)
Тема по справочнику тем датасетов Евросоюза
Тема по стандарту ISO 19115
ПО каталога данных
Язык (разговорный)
Источник данных
Формат файлов/стандарт API (если API)
Тип лицензии
Тип данных

Эти фильтры далеко не все что запланированы в Dateno, на подходе фасеты для поиска по сематическим типам данных, по временным промежуткам и многое другое.
Полнота
Сейчас в Dateno 19 миллионов наборов данных. Много это или мало? В поиске по датасетам от Google их 50 миллионов, крупных каталогах научных данных таких как ScienceBase их 18 миллионов, в индексах и поиске по научным данным вроде Datacite их около 30 миллионов. А на национальных порталах открытых данных обычно от 1 до 300 тысяч наборов данных, редко больше.
Индекс Dateno весьма велик, но далеко не полон. Более всего сейчас в нём данных с порталов открытых данных, порталов статистики и геоданных.
Тем не менее наша цель до конца года достигнуть планки в 30 миллионов наборов данных и это вполне реалистично.
Dateno сейчас - это уже готовый продукт с API, огромным поисковым индексом и пригодностью использовать его в работе. Ключевая возможность - это API поиска по датасетам, что позволит искать данные где бы они ни были и из любого продукта или интерфейса.
Я буду регулярно писать в этом блоге на русском языке о том как Dateno устроен, а в блоге на Medium на английском языке.
#data #datasearch #dateno #datadiscovery