

DuckDB на практике. Ограничения о которых важно знать

Я много пишу о DuckDB, особенно у себя в телеграм канале и не просто так, ведь DuckDB - это реально удобный и инструмент значительно упрощающий работу с большими базами данных на десктопах. Для аналитика - это один из ключевых современных инструментов, для разработчиков - это движок для встраивания в свои продукты, для дата инженера - инструмент автоматизации преобразования данных.
Но и такой инструмент как DuckDB не идеален и понимание его ограничений важный шаг в точном позиционировании его применения.
Я собрал небольшую подборку того что необходимо учитывать.
Только Юникод в CSV файлах

Да, всё верно, если вы собираетесь загружать CSV файлы в базу данных или делать к ним запросы через DuckDB - эти CSV файлы должны быть в кодироке UTF-8 или UTF-16, с недавних пор ещё может быть кодировка Latin1, но картины это не меняет. Если ваши CSV файлы, например, в кириллических кодировках Windows-1251 или KOI8, то до работы с ними их необходимо преобразовать и сделать это самостоятельно, потому что DuckDB определять кодировку и преобразовывать данные точно не будет. Почему так, неизвестно, это не самая сложная операция, но сейчас она точно не реализована. Поэтому, если вы работаете с большим числом CSV файлов кодировка которых вам неизвестна или может быть вариативно, предусматривайте идентификацию кодировки и их преобразование до обработки этих файлов с помощью DuckDB.
Не все JSON файлы будут считываться
По умолчанию DuckDB пытается преобразовать значения из JSON/JSON lines файлов в таблицу с идентификацией типов полей. Если у вас простой файл JSON в виде массива с перечислением объектов или если это простой JSON lines файл с построчными объектами, то проблем, скорее всего, не будет.
Но если у вас, например, JSON файл со структурой
{“total“ : 10000, “items“ : […]}
то не стоит рассчитывать что DuckDB поймёт что данные в атрибуте items. Он попытается реконструировать таблицу в виде одной записи с полями total и items и рассматривать items как массив значений. Сейчас нет опции передавать в функцию read_json путь к значениям для парсинга. Поэтому лучше знать какие именно JSON файлы вы подаёте на вход.
При автоопределении тип полей зависит от типа файла
Это может показаться странным, но это так. При автоопределении типов полей для JSON/JSON lines файлов DuckDB часто отмечает тип колонок как JSON даже если колонка содержит только строковые и нулевые значения.
Например, в этом файле поле Dataset и многие другие идентифицируются как JSON.

В то время как это же поле Dataset содержит только текстовые значения и NULL

Если бы мы также считывали не JSON lines, а CSV файл, то эти же поля были бы идентифицированы как VARCHAR. Эту разницу важно помнить если вы полагаетесь на механизм идентификации схем данных используемый в DuckDB.
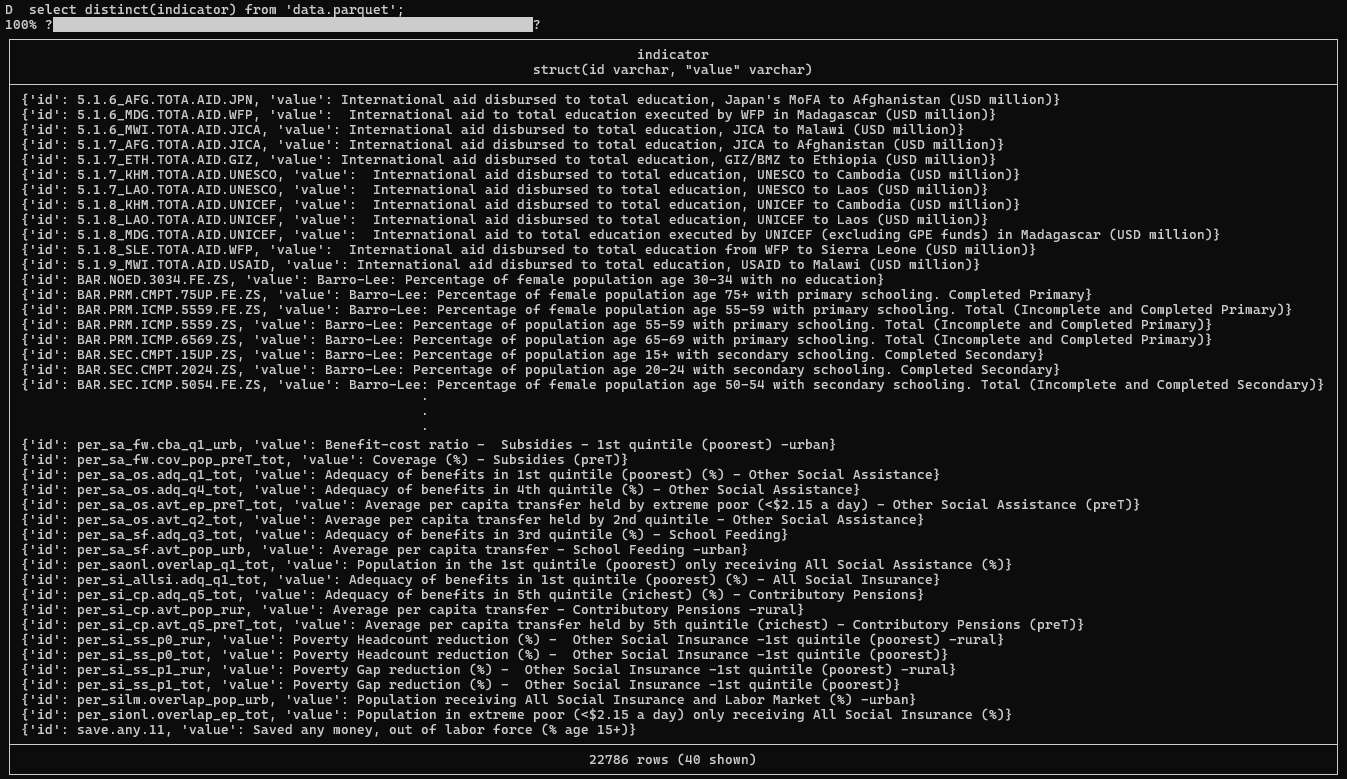
Не надо доверять количественным оценкам в SUMMARIZE
SUMMARIZE - это очень удобная команда в DuckDB выдающая сводку по значениям базы данных. В нашем случае результат команды summarize по всей базе значений индикаторов Всемирного банка выдаёт следующие значения

А последующий distinct запрос по полю indicator выдаёт другое значение. Потому что approx_unique - это прогностическое, а не реальное значение. Оно может не совпадать с реальным даже на небольших объёмах данных поэтому относится к нему необходимо с осторожностью.
Команды DESCRIBE и SUMMARIZE не дают полной схемы данных
В DuckDB есть две команды DESCRIBE и SUMMARIZE каждая из которых выдаёт схему данных. Первая делает это проще, вторая со сводкой значений, но у обеих есть специфика в том что они не разворачивают содержание вложенных структур.
Например, команда DESCRIBE в отношении файла с перечнем датасетов с каталога открытых данных Hubofdata.ru выдаёт 5 полей с вложенностью идентифицированные как STRUCT, но они не развернуты, в DuckDB сейчас отсутствует такая опция.
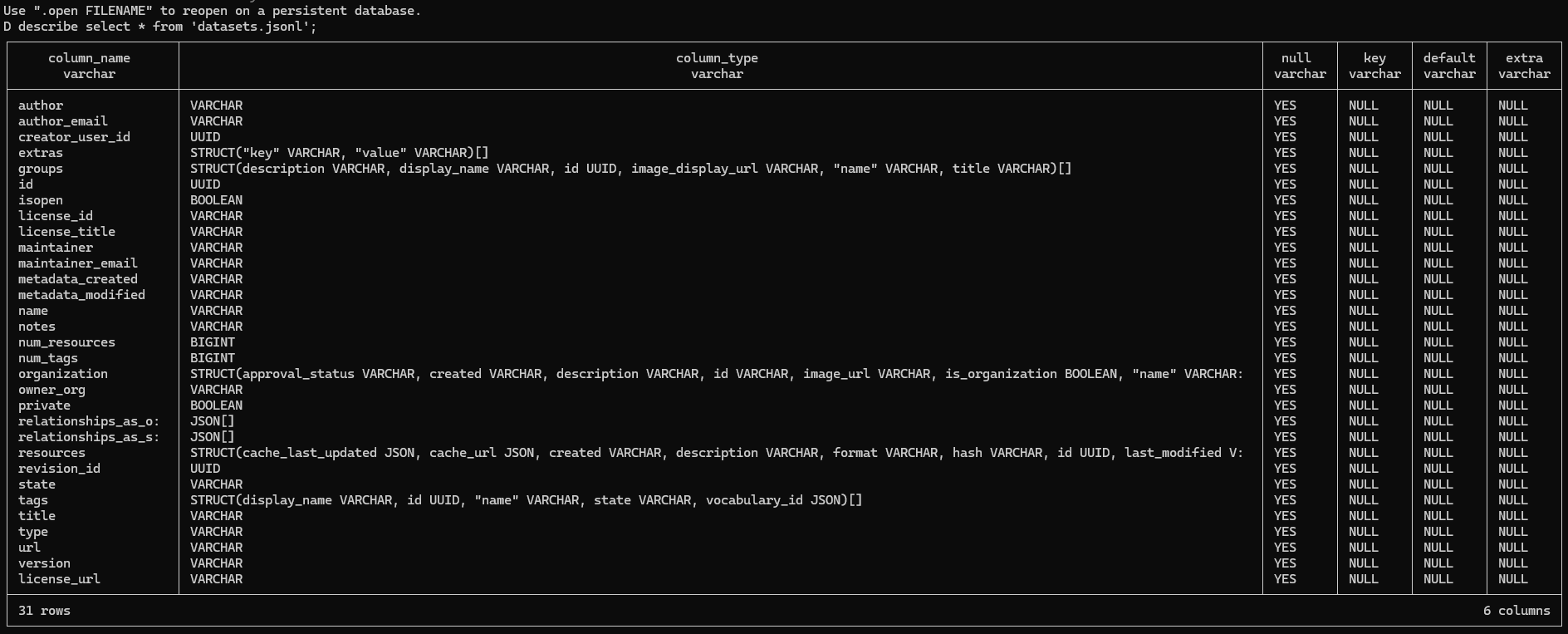
И если хочется увидеть подробности по этим вложенным полям то это необходимо делать запросами с разветыванием их структуры, командой unnest, добавляя recursive:=true если необходимо развернуть структуру с подструктурами.

Это ограничение для задачи исследования данных с помощью DuckDB. Например, для автоматизации перевода описания датасетов лично мне приходилось писать код постепенной развертки атрибутов типа STRUCT через последовательные unnest команды, чтобы собрать все названия всех вложенных атрибутов.
Перечисленный список ограничений не исчерпывающий, но важный тем кто использует DuckDB в повседневной работе.