Работаем с дата фреймами. Почему не Pandas и какие альтернативы?

Самый популярный инструмент для работы с аналитиков в последние годы - это программная библиотека Pandas для Python. Она, в связке с Jupyter Notebook уже давно стала чуть ли не стандартом для использования дата аналитиками, при обучении студентов, подготовке курсов по дата аналитике и не только. Но у Pandas всегда был один из важных недостатков - это низкая скорость работы на данных относительно большого объёма. Операции связанные в получением выборок из больших датасетов и операции с обработкой больших датасетов всегда были неспешными. На примере, в том числе, Pandas даже сложился миф что Python медленный язык поскольку Pandas был написан полностью на чистом Python.
Сейчас я лично всё чаще читаю/слышу и вижу в демонстрациях продуктов и кода что Pandas уже де-факто легаси. Нужный, живой, полезный, но непрактичный продукт для задач обработкой данных относительно большого объёма. У Pandas появилось много альтернатив развивающихся быстрее и существенно обгоняющих в скорости работы. Я приведу в пример ключевые из них.
1. Polars
Написанный на Rust движок для работы с дата фреймами и поверх которого реализованы программные библиотеки для наиболее популярных языков включая Python. Ключевое - это использование колоночного формата Apache Arrow для работы с данными и дополнительные возможности такие как выполнять SQL запросы к дата фреймам. По их собственным бенчмаркам с Polars быстрее Pandas многократно и сравним только с DuckDB.
2. Dask
Dask - это движок изначально созданный для параллелизации выполнения задач и реализации модели "big pandas", то есть как pandas только для данных большего объёма. Собственно главным конкурентом у Dask всегда позиционировался не Pandas, а Pyspark. Dask как бы создавался для конкуренции в потоковой обработке данных на серверах/кластерах. Но оказалось что большинство пользователей используют Dask на ноутбуках и с датасетами до 100GB.
3. cuDF
cuDF (читается как “KOO-dee-eff”) это библиотека для дата-фреймов в Python с использованием GPU (графического процессора). Создана в Nvidia в рамках проекта Rapids и интегрирована с Pandas и Polars. Судя по их собственным тестам обгоняет не только их, но и DuckDB, Clickhouse. Правда бенчмарк у них довольно ограниченный, всего на данных в 5GB, но тем не менее сейчас многие смотрят в эту сторону.
4. DuckDB
Строго говоря DuckDB - это не программная библиотека для дата-фреймов, а движок СУБД. Но устроен DuckDB так что его можно с ними сравнивать поскольку DuckDB имеет библиотеку для Python в рамках которой как умеет строить запросы поверх дата фреймов Pandas, так и возвращать дата фреймы после SQL запросов. У DuckDB есть свой бенчмарк по которым он быстрее большинства движков вроде Polars, Pandas и др. Но ещё и важно отметить что DuckDB делают акцент на скорости на больших объёмах применительно к настольным компьютерам. Не все движки проходят их тест по JOIN'у 50GB данных.
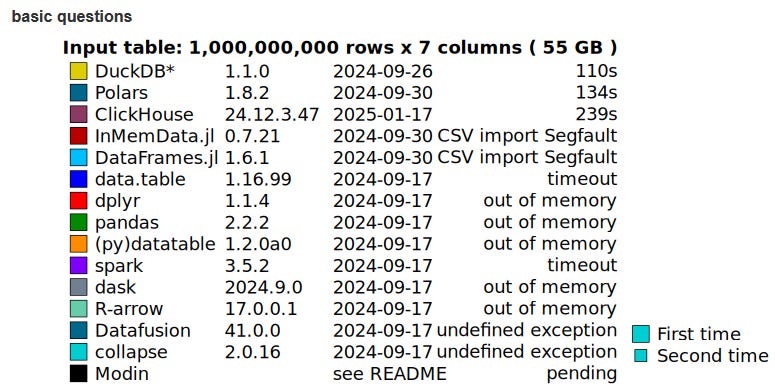
—
Это те движки и инструменты которые можно назвать основными.
Что важно, это то что у них всех есть немного разное позиционирование и практически отсутствуют универсальное сравнение. Нет кого-то нейтрального кто бы разработал пул тестов и проверил бы каждый движок. Зато в сети легко находятся частные сравнения 2-3 движков, чаще всего сделанные разработчиками одного из них. При всех сравнениях важно лишь помнить что "чистый Pandas" это наиболее медленный инструмент.
Один из способов взгляда на эти движки для дата фреймов это сравнение их с аналитическими базами данных такими как Clickhouse и для этого есть бенчмарки Clickbench где также есть обзор Pandas, Polars, DuckDB и нет разве что Dask. И там нет многих именно инструментов, а не баз данных, а то есть этот бенчмарк очень полезен, но и он полной картины не даёт.
А также другие альтернативы, о которых в этот раз без подробностей, просто ссылками:
Apache Datafusion - https://github.com/apache/datafusion
chDB - https://clickhouse.com/blog/welcome-chdb-to-clickhouse
Daft - https://github.com/Eventual-Inc/Daft
datatable (Python) - https://github.com/h2oai/datatable
data.table (R) - https://github.com/Rdatatable/data.table
Dplyr - https://dplyr.tidyverse.org/
Fugue - https://github.com/fugue-project/fugue
Ibis - https://github.com/ibis-project/ibis
Modin - https://github.com/modin-project/modin
Ray - https://www.ray.io/
Tibble - https://github.com/tidyverse/tibble
Vaex - https://github.com/vaexio/vaex
Выбирая между разными инструментами в итоге я могу порекомендовать DuckDB и Polars как наиболее производительные и зрелые одновременно.
Например, внутри Dateno мы используем DuckDB для исследований нашего поискового индекса и это позволяет проделывать эту работу без необходимости работы аналитиков с базой данных сервера, все ключевые запросы на оценку качества данных можно проделывать локально и это сильно убыстряет процессы работы с этими данными.
#dataengineering #dataframes #opensource #datatools