Data discovery в корпоративном секторе. Часть 1. Зачем всё это нужно?
Ничто не делается просто так. Просто нам не всегда известны мотивы. (с) Доктор Хаус

Рассказ о поиске данных в корпоративном секторе, обычно называемов data discovery, получится дличнным и я разделил его на несколько частей.
В первой части в о том зачем он нужен, как его обоснованнывать и как реализовывать. Тем кто уже решил этот вопрос, убедил руководство, или столкнулся с ситуацией когда решение этой задачи необходимо, можно смело пропустить эту часть. Те кто ещё только думает надо ли подобное реализовывать и есть ли у него/неё такие задачи, этот текст будет полезен.
Другая важная особенность этой темы в её сильной заполненностью маркетинговыми терминами, текстами и материалами, которые, с одной стороны важно читать и понимать, а с другой стороны относится к этому критично. Поэтому многие ссылки в этом тексте будут вести на сайты стартапов и крупных инфраструктурных игроков предлагающих каталоги данных.
Зачем необходим поиск данных в компаниях?
Поиск данных - это то что нужно всем кто так или иначе с данными работает: журналистам, учёным, программистам, аналитикам, инженерам да и просто любому квалифицированному пользователю. Те кто их ищут могут использовать для этого самые разные способы, от специализированных закрытых поисковых систем, до того чтобы поспрашивать знакомых. Цели также могут отличаться: учёный ищет данные и ссылки для научной статьи, журналист подтверждение/материал для расследования, аналитик API для подключения к Excel и так далее.
Чем отличается поиск данных в компаниях? Чем отличаются бизнес-потребители данных от кого-либо ещё?
У бизнеса возникают задачи поиска данных в двух основных случаях:
Поиск внешних данных для приобретения и создания создания собственных продуктов на данных. Основные способы получения внешних данных - это их покупка или же поиск бесплатных/открытых данных.
Поиск и исследование внутренних данных, это случаи когда возникла потребность систематизации и анализе данных во внутренней сети, проектах и продуктах, базах данных предприятия. А также, в расширенном толковании это распространяется на все процессы приобретения, обработки, передачи данных внешним контрагентам, доступ к данным и так далее.

Хотя обе эти цели имеют значение, чаще под корпоративным data discovery подразумевается потребности в инвентаризации и поиске именно внутренних данных, поскольку приобретение и поиск внешних данных хотя и важно, но актуально только для тех компаний которым это необходимо, не всем. А инвентаризация внутренних данных актуальна практически для всех цифровых компаний среднего размера.
Приобретение внешних данных
Первая цель, внешние данные, как правило, не требует специального внутреннего ПО и скорее требует наличия людей обученных навыкам приобретения данных, понимания основных оценок качества и знание систем поиска данных.
Приобретение внешних данных всегда сопряжено с поиском и анализом множества источников данных.
Идентифицировать владельца[-ев] данных, типа владельца и определить потенциальные источники.
Проанализировать каждый из источников и определить способ и возможность доступа к данным: открытые данные, общедоступные немашиночитаемые сведения, бесплатные данные по запросу, приобретаемые данные и тд. Способы этого анализа могут быть:
Исследовать сайты/порталы/веб-страницы с описанием данных
Спросить в профильных сообществах по открытым данным
Запросить консультантов/специализированные компании поставщики по добыче данные
Оценить стоимость приобретения данных, либо оценкой трудозатрат внутренней команды, либо ценовыми предложениями от потенциальных поставщиков.
Обеспечить получение данных и мониторинг, как технической так и юридической доступности данных.
Важно то что многие нужные данные не имеют машиночитаемой формы. Они могут публиковаться в виде HTML страниц, PDF документов или в других текстовых и даже графических форматах. Вы можете знать их местонахождение, они могут быть общедоступны, но не иметь нужной Вам формы. В этой случае приобретение данных сводится не к их покупке у первоисточника, а, либо работы внутренней команды по их парсингу, либо заказа этой работы как услуги с, как правило, ежемесячной оплаты подобной работы
Разбираем документы. Например, Ваша компания создаёт продукт по мониторинг качества жизни в регионах России. Вы понимаете что Вам нужны данные криминальной статистики по российским регионам. Где их взять? Вы знаете сами или узнаете у специалиста или в профильных сообществах что эти данные публикуются на сайта Crimestat.ru и на сайте МВД России. Но на сайте Crimestat.ru они не обновляются c начала 2023 года, а на сайте МВД России публикуются в виде PDF отчетов. Поскольку Вам нужны актуальные данные то сайт Crimestat.ru не подходит. Теперь Ваша задача оценить стоимость преобразования PDF с сайта МВД России внутренними силами или на рынке услуг парсинга/разработки парсеров сайтов и документов под заказ.
В некоторых случаях можно вступать в коммуникацию с владельцами данных для получения их в лучшем качестве или в более удобных форматах. В случаях органов власти всегда существует модель взаимодействия через запросы данных, а также письма контактным лицам ответственных за их размещение. Это может как иметь, так и не иметь успех.
Множественный выбор. Например, Ваша компания консультирует корпорации по экономическому состоянию территорий/стран куда те планируют выходить со своими продуктами. Для этого Вы ищите и используете доступные открытые или коммерческие данные. Вы находите что существует много поставщиков таких данных, начиная с национальных стат. служб стран и продолжая системами данных ООН, Всемирного банка, ряда банков развития. А также присутствуют несколько коммерческих поставщиков приводящих эти данные в нормализованный и более удобный вид, и поставщиков альтернативных данных, не использующих официальную статистику. Вы сводите источников данных в таблицу и взвешиваете их качество, оперативность, гранулярность и стоимость для окончательного решения. В итоге Вы можете выбрать в качестве источника, как открытые данные, так и коммерческую услугу, и иметь альтенативы в случае проблем с выбранным источником данных.
Относительно каждого из источников данных, всегда важно иметь финансовую оценку риска его исчезновения, наличия альтернатив. Именно оценка финансовых рисков, стоимости приобретения, контроля качества и поддержания доступа и есть ключевые отличия корпоративного обнаружения и приобретения данных от других потребителей.
Важно помнить что приобретение внешних данных очень сильно зависит от рынка, наличия/отсутствия этих данных в принципе, наличия открытых данных или коммерческих поставщиков. Примеры использования и приобретения могут сильно отличаться, а поиск данных включать, как относильно стандартные способы, так и специализированные сервисы и посредников.
Более подробно о том как взаимодействовать с поставщиками, контролировать качество и управлять рисками будет в отдельной главе в одном из следующих текстов.
Поиск и исследование внутренних данных
Поиск и исследование внутренних данных - это именно то что является основным коммерческим предложением продуктов в категориях каталоги данных (data catalogs)1 и связанных с ними более комплексных продуктов (data intelligence, data observation platforms, data platforms, data workspaces) и так далее.
Большое разнообразие названий не должно отпугивать, это не более чем маркетинговые термины и некая вариативность возможностей, поскольку ряд поставщиков решений предлагают комплексные продукты по полному контролю над данными компаний, но это не меняет области их применения для описываемых здесь задач.
Основные функции каталогов данных
Это включает решения множества задач применяемых в зависимости от специализации продукта. Задачи решаются через следующие функции подобных продуктов:
инвентаризация существующих баз данных, таблиц, представлений, сохранённых процедур, конвейеров данных, источников получения данных, направлений передачи данных, обработчиков и иных артефактов и объектов сбора, хранения, обработки и передачи данных.
классификация сохранённых объёктов на предмет наличия персональных данных, смысловых (семантических) типов данных, областей применения, проектов
мониторинг изменений схем данных, добавления новых и удаления существующих объектов сбора, хранения, обработки и передачи данных
мониторинг прослеживаемости данных (data lineage) с возможностью идентификации первоисточника данных
мониторинг файлов данных на общих и частных хранилищах, реже мониторинг условно любых пригодных к анализу данных, в которых могут содержаться чувствительные сведения
а также профилирование, документирование данных и управление метаданными.
Эти и многие другие функции реализуются в продуктах дата каталогов. Ещё важно помнить что хотя этот тип продуктов называют каталогами данных, на самом деле, по смыслу, это каталоги метаданных, поскольку они содержат данные о данных, не содержание таблиц из баз данных, а то как данные описаны, из чего состоят, схемы, структуры, классификация, документация, условия, связи и многое другое.
Отдельно можно выделить каталоги данных по критериям облачного и корпоративного внедрения. Поскольку очень многие компании сейчас используюь один или несколько облачных хранилищ таких как AWS, Azure, Snowflake, Google Cloud, а также многочисленные облачные сервисы из Modern Data Stack, то есть категория каталогов данных которые можно называть Cloud-only. Они являются, либо частью одной из SaaS платформ, например, Amazon Data Catalog, Google Data Catalog, Oracle Data Catalog; либо они умеют работать с разными облачными каталогами и сами находятся в облаке, например, Cloudera, Secoda и многие другие.
Типы потребностей при внедрении каталогов данных
Работу с внутренними данными можно разделить на три-четыре основных потребности:
Compliance. Поиск, систематизация и анализ всех внутренних баз данных, ресурсов и процессов для соответствия регуляторным требованиям таким как GDPR. К этой категории продуктов каталогов данных можно отнести такие решения как Collibra, Inmuta, Securiti. Несоблюдение регуляторных требований может приводить к серьёзным штрафам и другим неприятным последствиям2.
Analytical needs. Решение задач связанных с работой аналитиков, возможность для них быстро находить необходимые данные, оценивать их качество, прослеживать их первоисточник при необходимости. Это такие продукты как Data.world, Datalogz, Datahu. Бывает и так что каталоги данных для аналитиков являются частью BI продуктов3.
Engineering needs. Решение проблем с прерыванием конвейеров данных, изменением схем, качеством данных, систематизацией источников, баз данных, получателей данных и других объектов. Например, такие продукты как Datakin, OpenLineage, Monte Carlo. В гайдах к коммерческим продуктам немало расказывается о применении каталогов данных дата инженерами4
ML needs. Популярный подвид потребности для аналитиков и инженеров, но с акцентом на data science, а то есть когда основные выгодоприобретатели от хороших данных и стабильно работающих конвейеров по поставке данных являются ML специалисты. Особенность в том что контроль доступности и поставки данных формируется вокруг автоматизированных процессов и продуктов машинного обучения.
Все эти потребности не существуют сами по себе и очень часто пересекаются. Большая часть продуктов дата каталогов закрывают (пытаются закрыть) как минимум две из них.
В чьих интересах внедряют каталоги данных и кто пользователи
Потребности использования каталогов данных и решение задач поиска данных напрямую происходят от основных их пользователей, их можно определить следующим образом:
Data analytics - поиск нужных данных, контроль их качества, документирование/использование документации
Business analytics - поиск данных, контроль качества данных, интеграция с системами визуализации, использование бизнес-глоссариев работы с данными.
Data engineers, DataOps, DevOps - контроль качества данных, процессов их обработки, конвейеров данных,
Data scientists and ML specialists - поиск данных для машинного обучения, отслеживание конвейеров обработки данных и машинного обучения
Privacy and security officers - отслеживание персональных данных, данных составляющих корпоративную тайну, контроль доступа к данным, подготовка compliance отчетов.
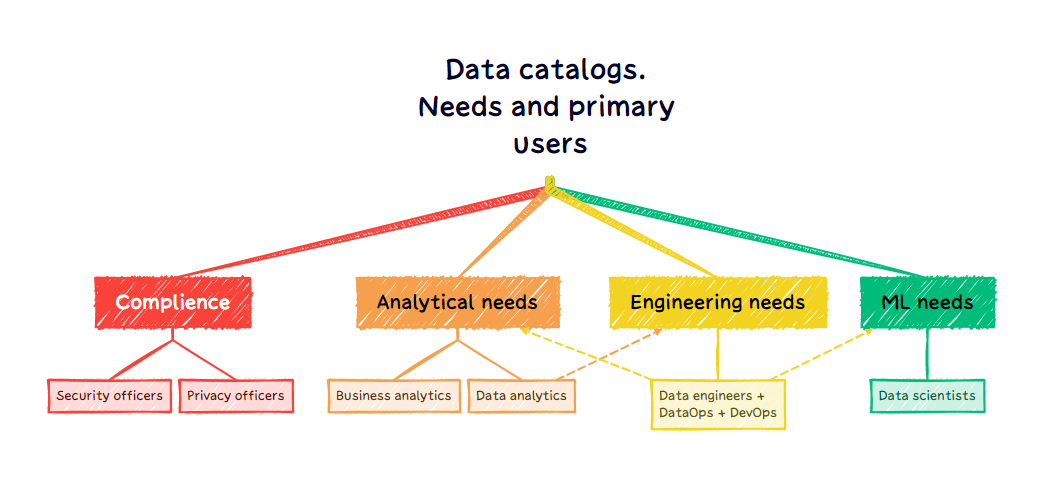
Поскольку каталоги данных, как правило, решают не менее двух потребностей, то чаще всего активными пользователями являются несколько групп интересантов.
Рассмотрим несколько примеров, я специально описываю их обезличенно, но все они взяты из реальной жизни.
Утечки и риски. Среднего размера компания поддерживает множество баз данных, обрабатывает данные с помощью ETL продуктов и имеет несколько команд разработчиков и аналитиков. В течение года у компании происходит несколько утечек данных, как минимум одного из специалистов ловят на злоупотреблениях в использовании данных клиентов и другие инциденты. Руководство компании хочет повысить безопасность работы с данными и выбирает продукт дата каталога из категории Compliance. После разворачивания продукта и анализа баз данных и процедур обработки, ответственный за приватность данных в компании (CPO) устанавливает или актуализирует, при наличии, правила работы с данными. Каталог внедряется, в первую очередь, для того чтобы упростить работу CPO и ответственного за безопасность данных (CTO) и его внедрение устанавливает определенные правила работы для аналитиков, программистов и инженеров.
В данном случае основным движущим фактором является осознание руководством компании необходимости в контроле работы инженеров, аналитиков и разработчиков над данными и оперативном выявлении случаев когда персональные данные выходят за пределы защищённого контура.
—
Много лишней работы. Средняя ИТ компания специализируется на продуктах на данных, продаёт их в виде сервисов, в виде доступа к базам данных напрямую, в виде дампов данных. Многие данные являются производными из многих разных источников, много унаследованных продуктов и ресурсов и несколько команд разработчиков. Технический директор всё чаще сталкивается с многократным дублированием одних и тех же данных полученных из одних и тех же источников разными командами, а также с тем что процесс онбординга (приёма на работу нового сотрудника и включение в работу) занимает всё большее время из-за фрагментированного описания данных, их обработки и так далее. Технический директор принимает решение о внедрении каталога данных с акцентом на автоматизацию подготовки документации, поиска дублей, отслеживания конвееров обработки данных. Заодно он решает ещё одну задачу, мониторинга процессов обработки данных и выявления сбоев в этих процессах. Для закрытия этой потребности технический директор выбирает продукт каталога данных с функциями data observability, отслеживания процессов работы с данными.
В этом примере решаются, в первую очередь, инженерные задачи, но частично затрагиваются задачи аналитиков которые также являются потребителями хорошей документации и удобного поиска.
—
Отчёты нужны быстрее. Крупный ритейловый холдинг на непрерывной основе собирает большие объёмы данных со всех каналов продаж, систем учёта, статистики посещамости, профилей каждого пользователя и других источников. С этими данными работает несколько команд бизнес и дата аналитиков по итогам работы которых компания актуализирует цены, формирует индивидуальные предложения, оптимизирует цепочки поставок и проводит другие автоматические и автоматизированные операции. До того как аналитики работают с данными те готовятся дата инженерами и могут дублироваться и схожие данные могут поступать из разных источников, например, из нескольких систем счетчиков на сайте и в мобильных приложениях. Схемы данных регулярно меняются, а источники данных не всегда доступны и полны. Отсутствие документации к данным часто приводит к удлинению сроков подготовки аналитики. Руководство компании, заинтересованное в непрерывной работе холдинга, принимает решение о внедрении системы каталога данных для того чтобы аналитики могли быстрее обращаться к командам дата инженеров в случаях возникновения ошибок в сборе данных.
Этот пример проистекает от бизнес потребности руководства компании и руководителей продуктов в получении оперативной аналитики, а также для решения задач когда результаты этой аналитики применяются к предложениям компании. Так работают, например, продукты в категории Reverse ETL.
—
Всё необходимо заменить. Крупному госучреждению со специализацией на сопровождении и поддержке множества информационных систем предстоит мигрировать эти информационные системы в новую единую информационную систему. При этом по предыдущим системам документации мало, она неактуальна, фрагментирована, а разработка велась на устаревших инструментах и многие системы не имеют поддержки со стороны разработчиков. Руководитель проекта новой информационной системы инициирует создание каталога данных для инвентаризации содержания существующих информационных систем для того чтобы спроектировать перенос их данных и функций в новую систему, автоматическому пониманию смысловых (семантических) значений таблиц, колонок с данными и представлений, а также автоматическому созданию документации. Для этого руководитель проекта выбирает каталог данных с функциями автогенерации документации и внедряет каталог данных как временное решение помогающее ему в миграции на новую информационную систему.
В данном случае нужны вполне определённые функции у ПО для каталогизации данных. Оно выбирается как промежуточное решение в процессе миграции с одних информационных систем на другие.
Эти примеры не исчерпывают все модели внедрения каталогов данных и все потенциальные потребности в поиске данных, но демонстрируют некоторые реалистичные сценарии.
Как понять нужен ли вам каталог внутренних данных и их инвентаризация?
Прежде чем инвентаризировать данные нужно понять, а нужно ли это вообще. Возможно масштаб задач этого совершенно не требует.
Самый простой способ это понять в том чтобы задать себе несколько вопросов:
Есть много разных баз данных и обработчиков данных, написаны за разные годы, часто уже без тех кто их разрабатывал.
Многие базы данных дублируются, документация на них фрагментирована
Часто возникают ситуации когда невозможно быстро найти ответственного за создание какой-либо базы данных или конвейера их обработки.
Регулярно возникают вопросы без ответа о том откуда берутся данные и куда они уходят.
У компании были утечки данных или инциденты со злоупотреблением доступом к персональным данным
Общее число специалистов разработки, аналитики и инженеров данных превышает 50 человек.
Если хотя бы на 3 из этих вопроса Вы ответили да, то определённо Вам стоит задуматься о внедрении каталога управления данными, хотя бы в самом простом и бесплатном варианте.
Как говорить о том зачем нужен корпоративный каталог данных
Итого, один из важнейших вопросов, во внутренней коммуникации, в как аргументировать внедрение инструментов data discovery таких как дата каталоги:
Если компания должна соблюдать требования GDPR и аналогичного регулирования в других странах и регионах, то мониторинг всех баз данных - это один из способов соблюдения регуляторных требований.
Если были утечки данных, то это один из инструментов их предотвращения. Безусловно не единственный, но важный.
Если потребность аналитиков в качественной документации созрела и можно привести факты/измерить качество работы из-за отсутствия актуальной документации и сложности в поиске данных. Это измеримо в изменении того сколько времени тратится на поиск данных.
Если инциденты с поиском ответственных за данные, за конвейеры их обработки участились, причём регулярно возникают ситуации когда быстро эти инциденты не решаются.
Если баз данных очень много, сотни и тысячи, если конвейеров обработки данных также много, то каталогизация данных нужна даже если ещё нет интенсивной аналитической работы. Потому что она неизбежно возникнет в этих условиях. Это позволит компании значительно быстрее сформировать аналитическое подразделение когда такое решение будет принято.
Итого
В этой части я постарался насколько возможно подробно изложить основу того зачем внедряют инструменты data discovery, зачем это нужно в корпоративном секторе и для каких потребностей внедряют каталоги данных.
В следующих частях будут раскрыты следующие темы:
Обзор технических продуктов по каталогизации данных, с акцентом на продукты с открытым кодом.
Особенности, сложности и ограничения применения каталогов данных
Подробнее о том как искать данные для коммерческих продуктов на данных
Особенности инвентаризации данных в госсекторе.
Этот текст часть гайда по поиску и инвентаризации данных данных. Пожалуйста, оцените был ли он полезен, а если Вы нашли неточности, неполноту, ошибки или другие недостатки, пожалуйста, напишите об этом в комментарии
What Is a Data Catalog and Why Do You Need One? https://www.oracle.com/big-data/data-catalog/what-is-a-data-catalog/
Data Governance and Compliance: Act of Checks & Balances https://atlan.com/data-governance-and-compliance/
Metric insights. What is a data catalog? https://www.metricinsights.com/what-is-a-data-catalog/
A Complete Guide To Data Engineering https://www.secoda.co/blog/a-complete-guide-to-data-engineering-metadata-management-and-data-catalogs